Гравитационная модель Хаффа
1 Исходные данные
В качестве исходных данных нам необходимы:
жилые дома - место жизни наших потенциальных покупателей;
улично-дорожная сеть, которая будет использоваться для расчета времени в пути от жилого дома до магазина;
слой с локациями торговых точек.
Первые два слоя необходимо скачать из OSM аналогично исходным данным в предыдущей работе или же можно взять из предыдущей работы готовые данные.
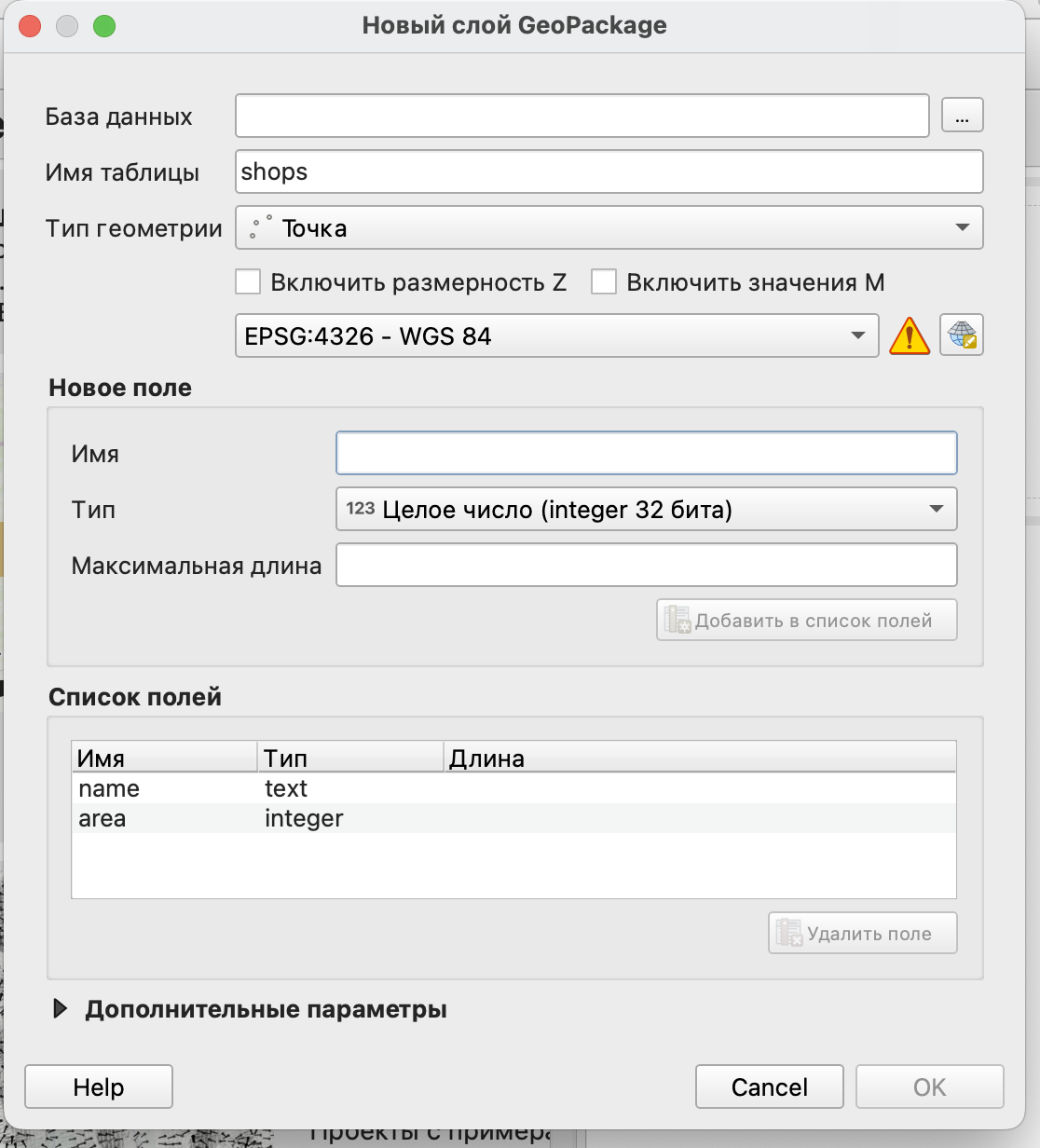
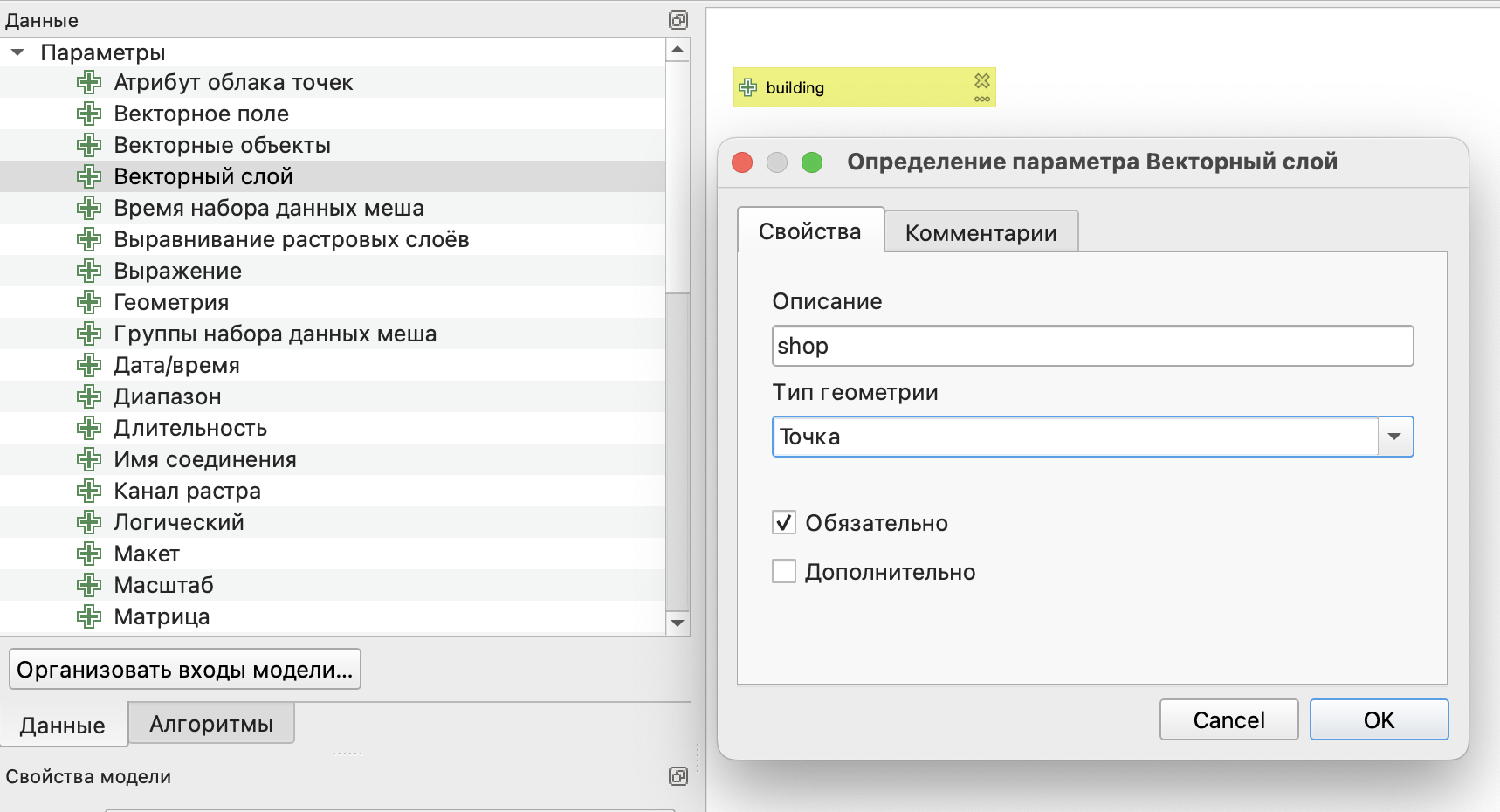
Слой с локациями торговых точек мы создадим самостоятельно. Для этого в строке меню необходимо выбрать Слой \(\longrightarrow\) Создать слой \(\longrightarrow\) Создать слой GeoPackage.
Далее в открывшемся окне следует указать характеристики слоя:
база данных - это путь к файлу, в котором будет храниться слой;
имя таблицы - название слоя, которое будет отображаться в панели слоев;
тип геометрии - нам нужны точечные объекты;
система координат - можно оставить географическую систему координат по умолчанию, она будет совпадать с системой координат данных, скачанных из OSM;
список полей, который будет включать два обязательных для нас поля - name (название магазина, текстовый формат данных) и area (площадь магазина в метрах квадратных, целое число).
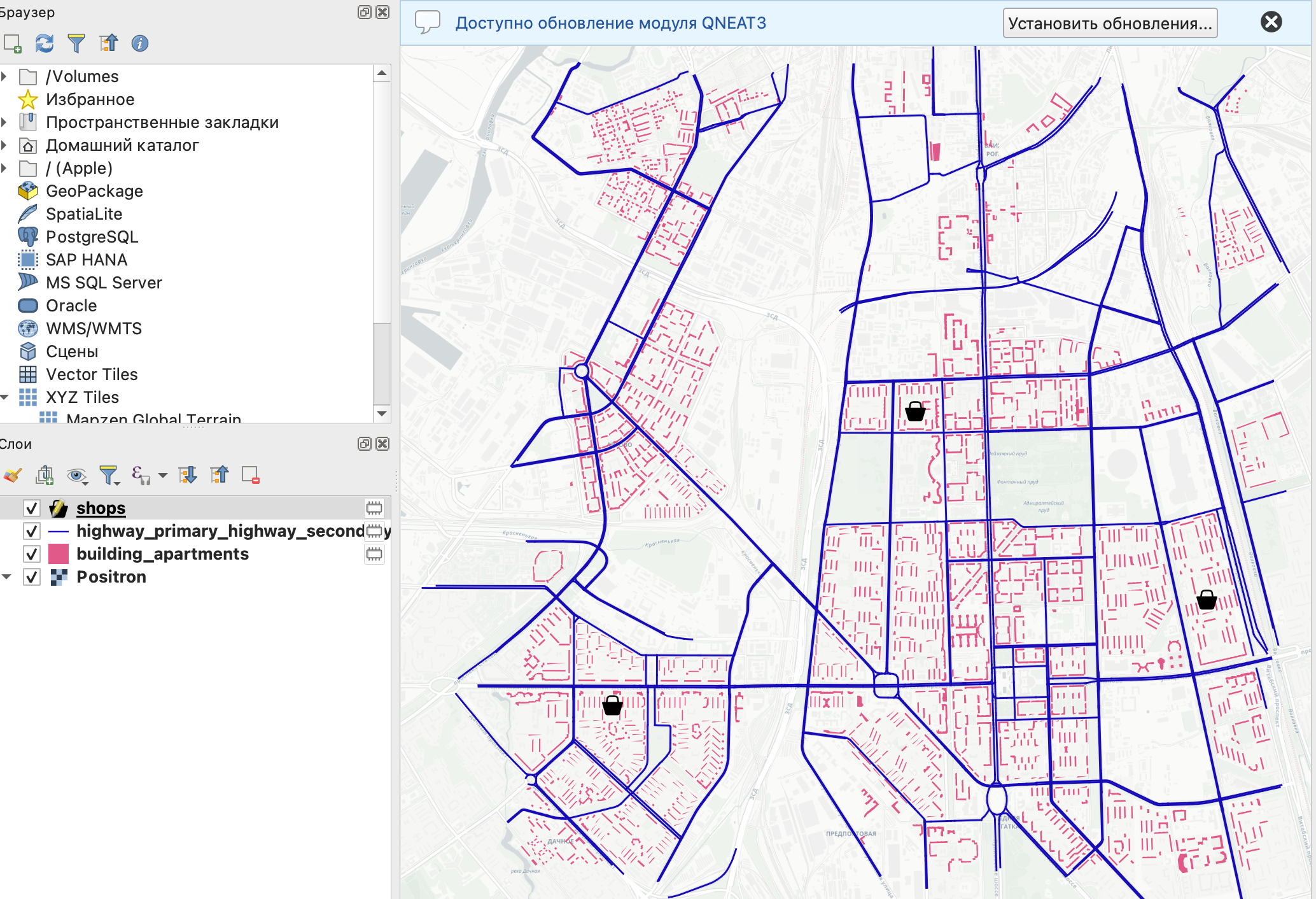
После создания слоя, его необходимо будет сделать редактируемым и нарисовать на карте несколько точек в разных частях исследуемой территории и заполнить для них атрибутивные данные - название магазина и площадь.
Названия точек должны быть уникальными, в противном случае модель не будет работать.
2 Построение геомодели
В этой работе мы будем оценивать вероятность посещения того или иного магазина, исходя из их доступности и площади (как прокси-метрики разнообразия ассортимента), с использованием гравитационной модели Хаффа.
\[P_{ij} = \frac{\frac{S_{j}}{T^\lambda_{ij}}}{\sum_{j}^{n}\frac{S_{j}}{T^\lambda_{ij}}}\]
- \(P_{ij}\) - вероятность того, что покупатель из локации \(i\) пойдет в магазин \(j\);
- \(S_{j}\) - площадь магазина \(j\);
- \(T_{ij}\) - время/расстояние, которое нужно преодолеть, чтобы попасть в магазин;
- \(\lambda\) - параметр, отражающий влияние времени в пути на покупателя.
Мы воспользуемся упрощенной моделью, приняв параметр \(\lambda\) равным единице, так как у нас нет подробных данных о предпочтениях покупателей.
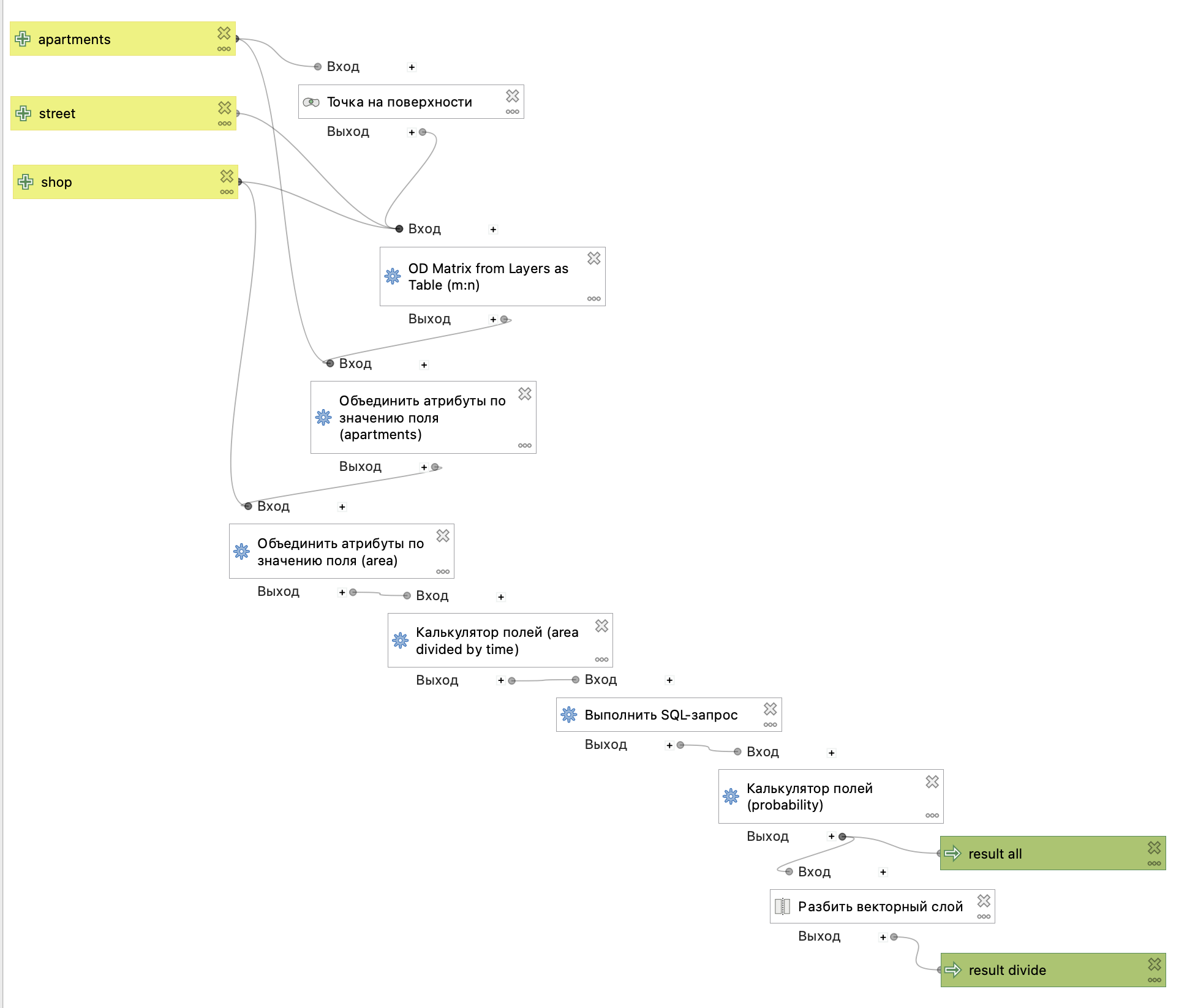
Для построения моделей будем использовать редактор моделей.
Редактор моделей позволяет выстроить последовательный процесс вычислений из цепочки операций с помощью простого графического интерфейса.
Полученная геомодель позволяет автоматизировать вычисления и избежать вывода промежуточных результатов.
Подробнее про построение геомоделей можно в документации
Открыть редактор моделей можно из строки меню Анализ данных \(\longrightarrow\) Конструктор моделей или по клику на кнопку Модели в Панели инструментов анализа.
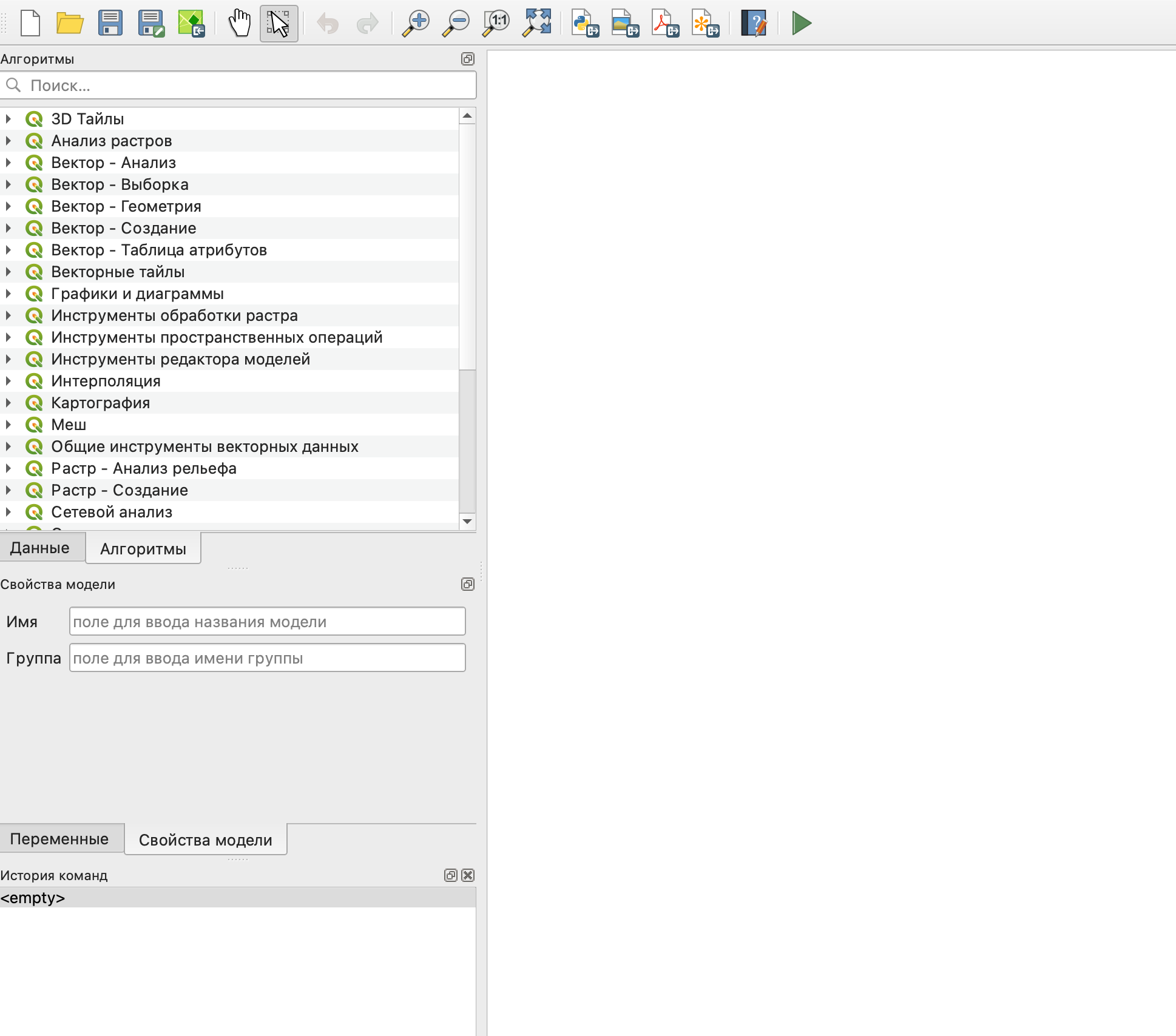
В открывшемся новом окне основная часть предназначена для отображения модели в графическом виде, слева панель данных и алгоритмов (переключаются по вкладкам внизу панели), свойства и переменные модели, а также история команд.
2.1 Входные данные
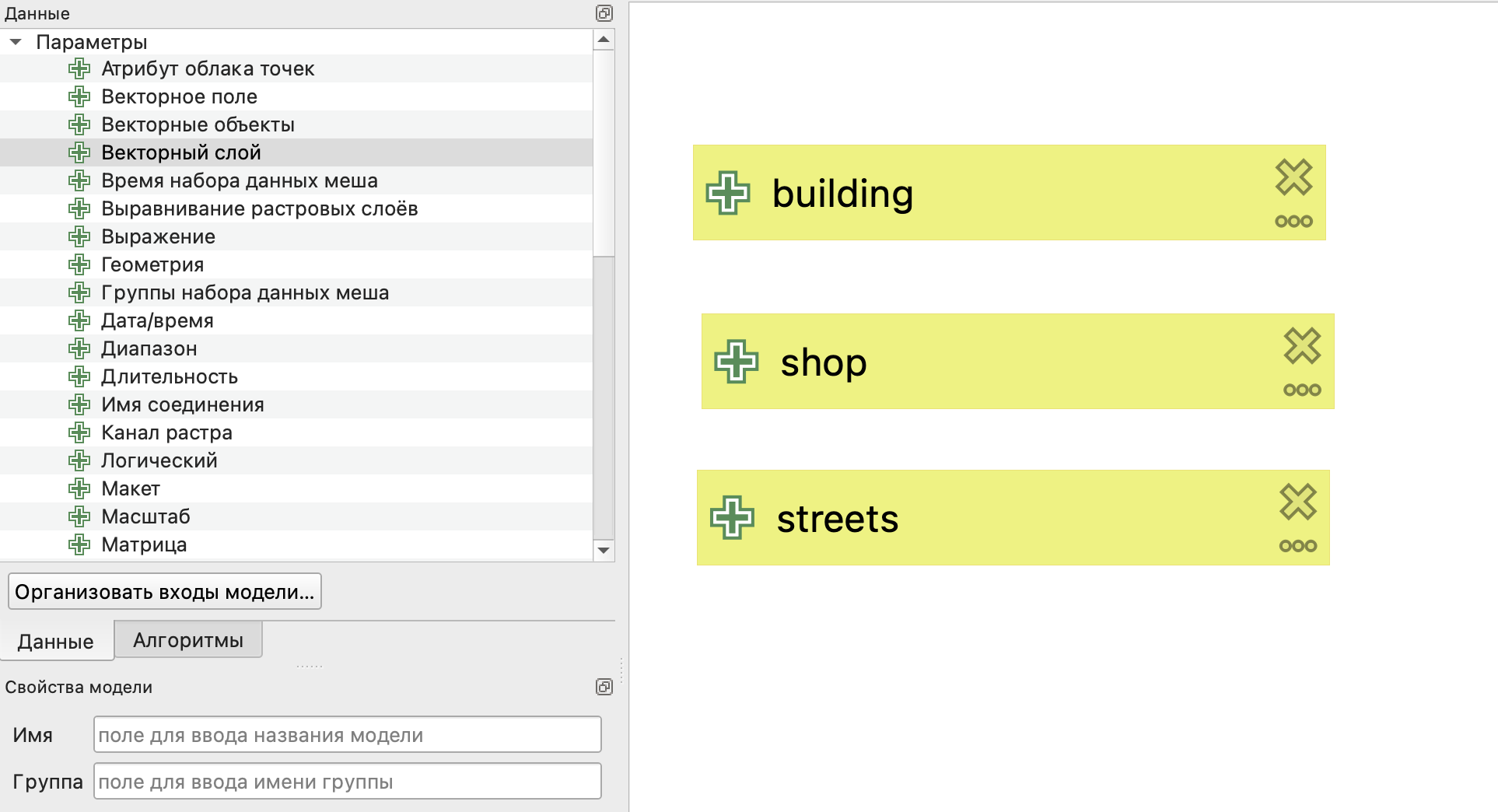
В первую очередь зададим для нашей модели входные данные. В нашем случае все входные данные будут представлены в виде векторных слоев:
здания - обязательный параметр, полигоны;
магазины - обазятельный параметр, точки;
улично-дорожная сеть - обязательный параметр, линии.
Обязательный параметр - это тот, без включения которого в исходные данные запуск модели осуществляться не будет.
Желательно называть входные данные буквами английского алфавита, так как иногда они могут не добавляться в модель или работать некорректно при использовании кириллицы.
Входные данные в модели обозначаются зеленым плюсом перед названием.
2.2 Расчет матрицы старт-назначение между потребителями и сервисами
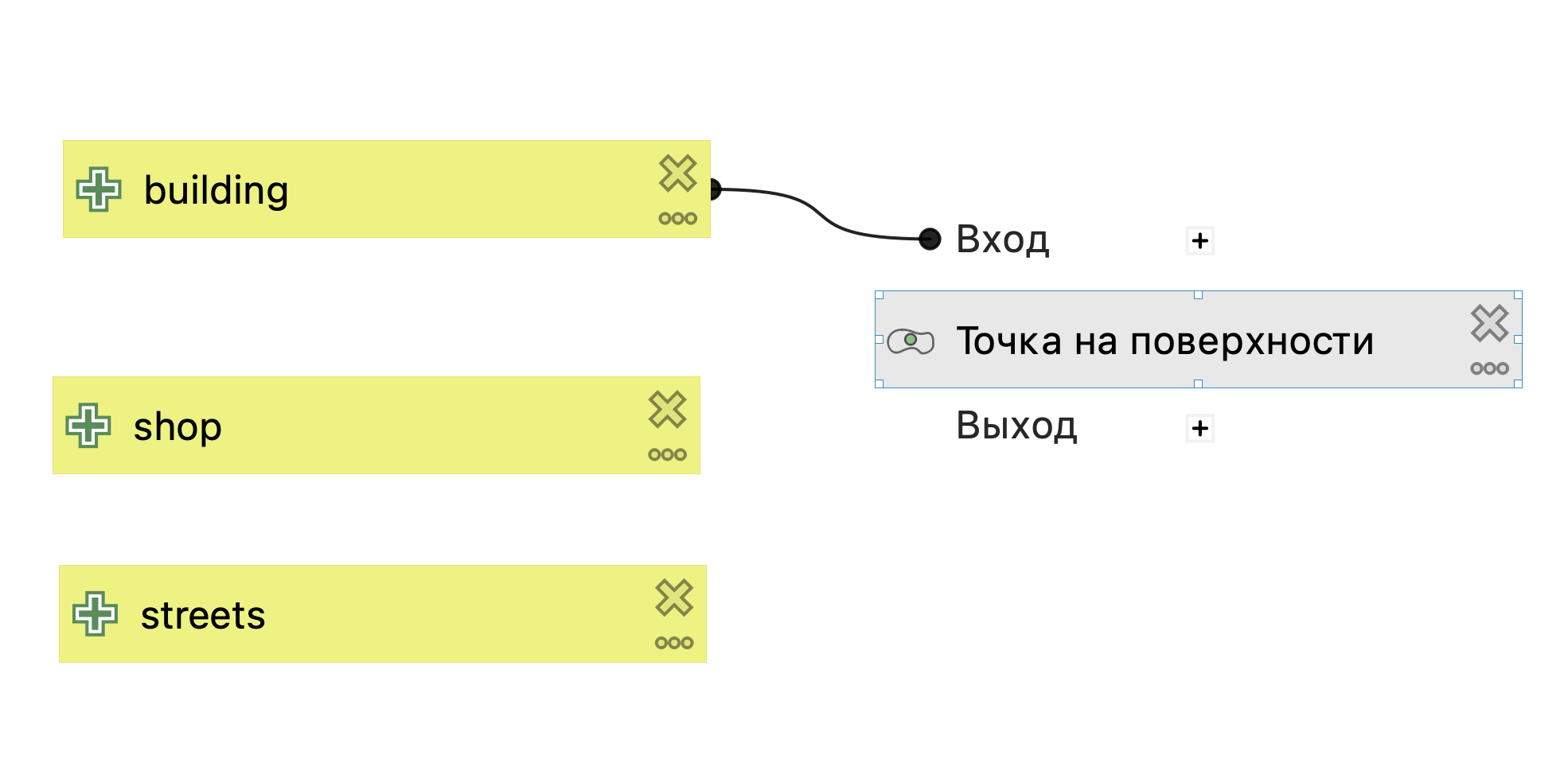
Также как и для анализа размещения-распределения нам необходимо преобразовать полигональные здания в точечные объекты с помощью инструмента Точка на поверхности.
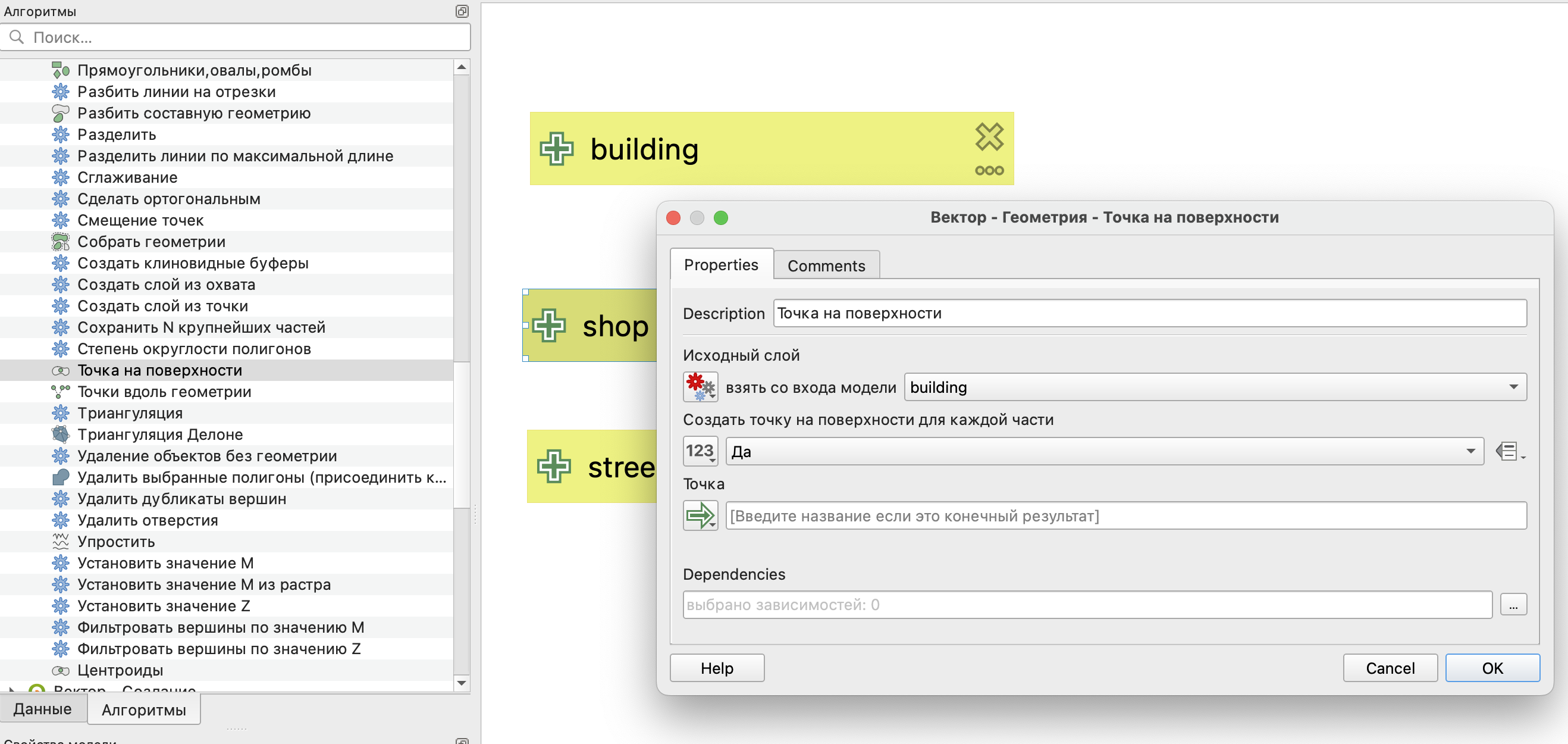
В модели появится первый шаг, соединенный с одним из исходных параметров.
Далее мы можем непосредственно рассчитать матрицу старт-назначение с использованием плагина QNEAT3.
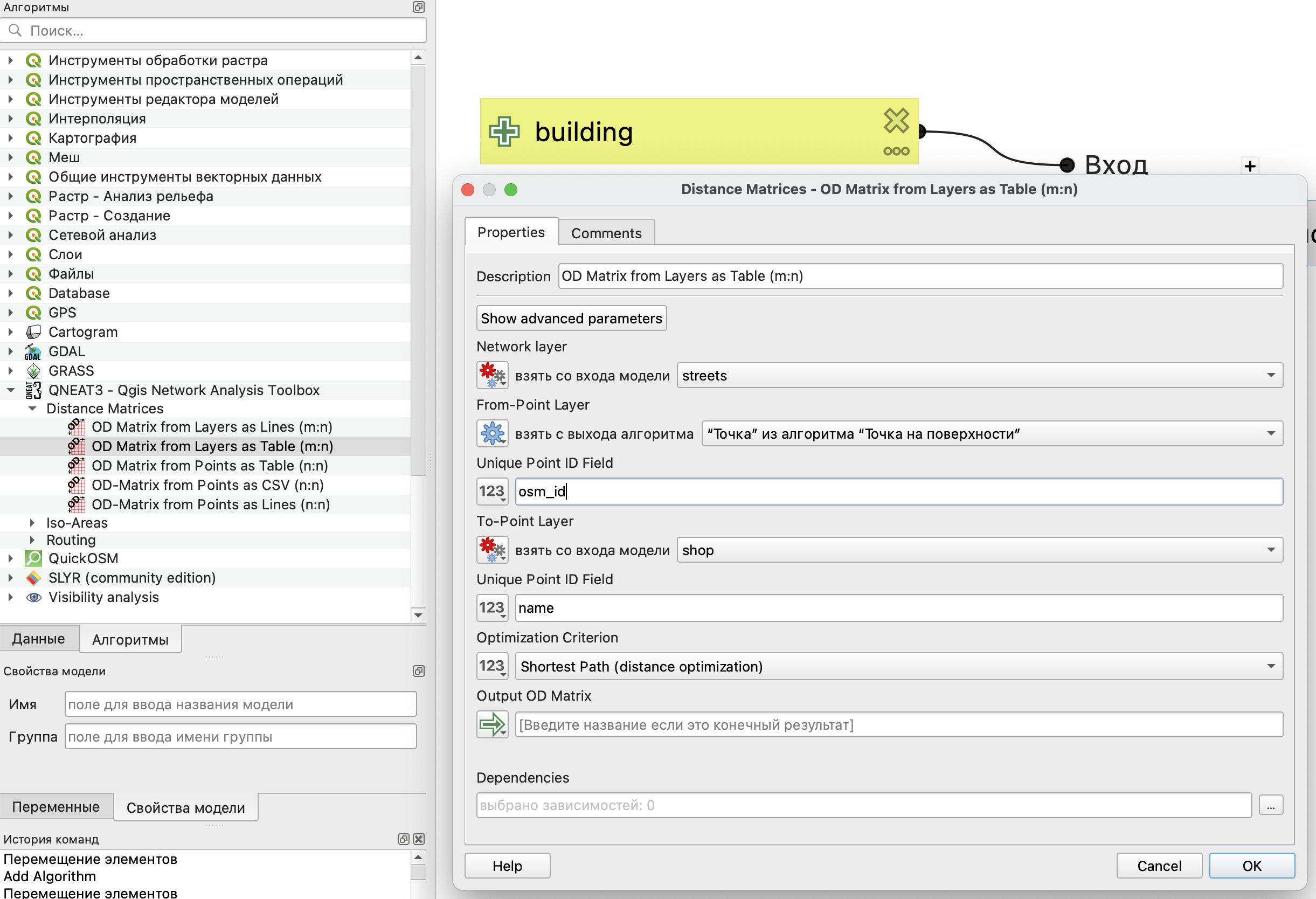
Параметры здесь указываются аналогично тому, как указывались просто в инструменте для построения матрицы.
Так как нам здесь нет необходимости впоследствии визуально отображать пути покупателей от жилых домов до магазинов, то строить матрицу будем просто в виде таблицы на основе двух слоев.
Идентификаторы объектов стартовых и конечных точек должны быть уникальными (внутри слоя естественно).
В нашем случае для стартовых точек (домов) будет использовать osm_id, который всегда будет уникальным и есть в этом слое, так как данные брались из OSM, а для магазинов будет использоваться поле имени name (поэтому нам очень важно, чтобы в этом слое названия магазинов были уникальными).
Так как в качестве стартовых точек мы используем не непостредственно здания, а результат применения инструмента Точки на поверхности, то необходимо выбрать, что здесь мы хотим использовать результаты выхода этого алгоритма.
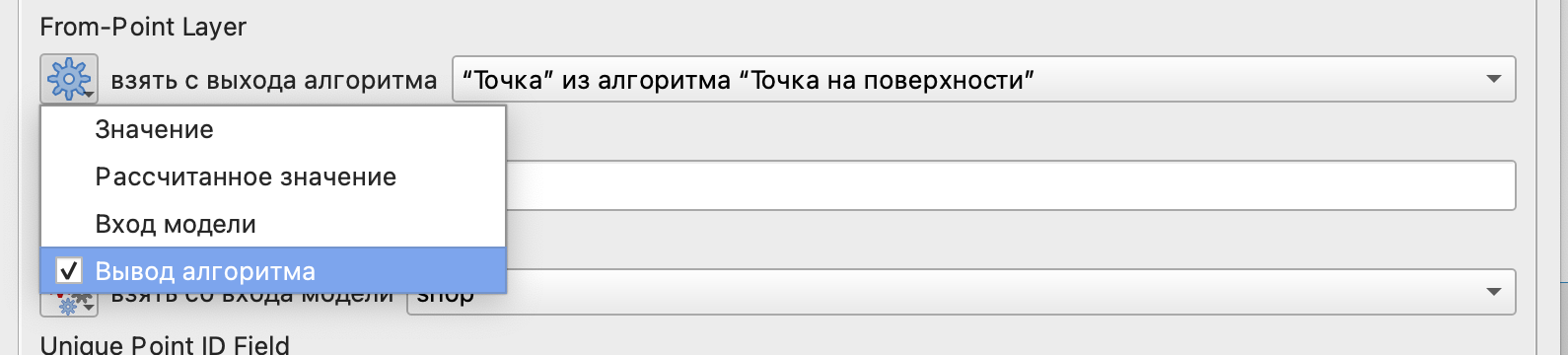
Полученный результат будет представлен только в виде таблицы без атрибутов, которую можно присоединить к одному из векторных слоев.
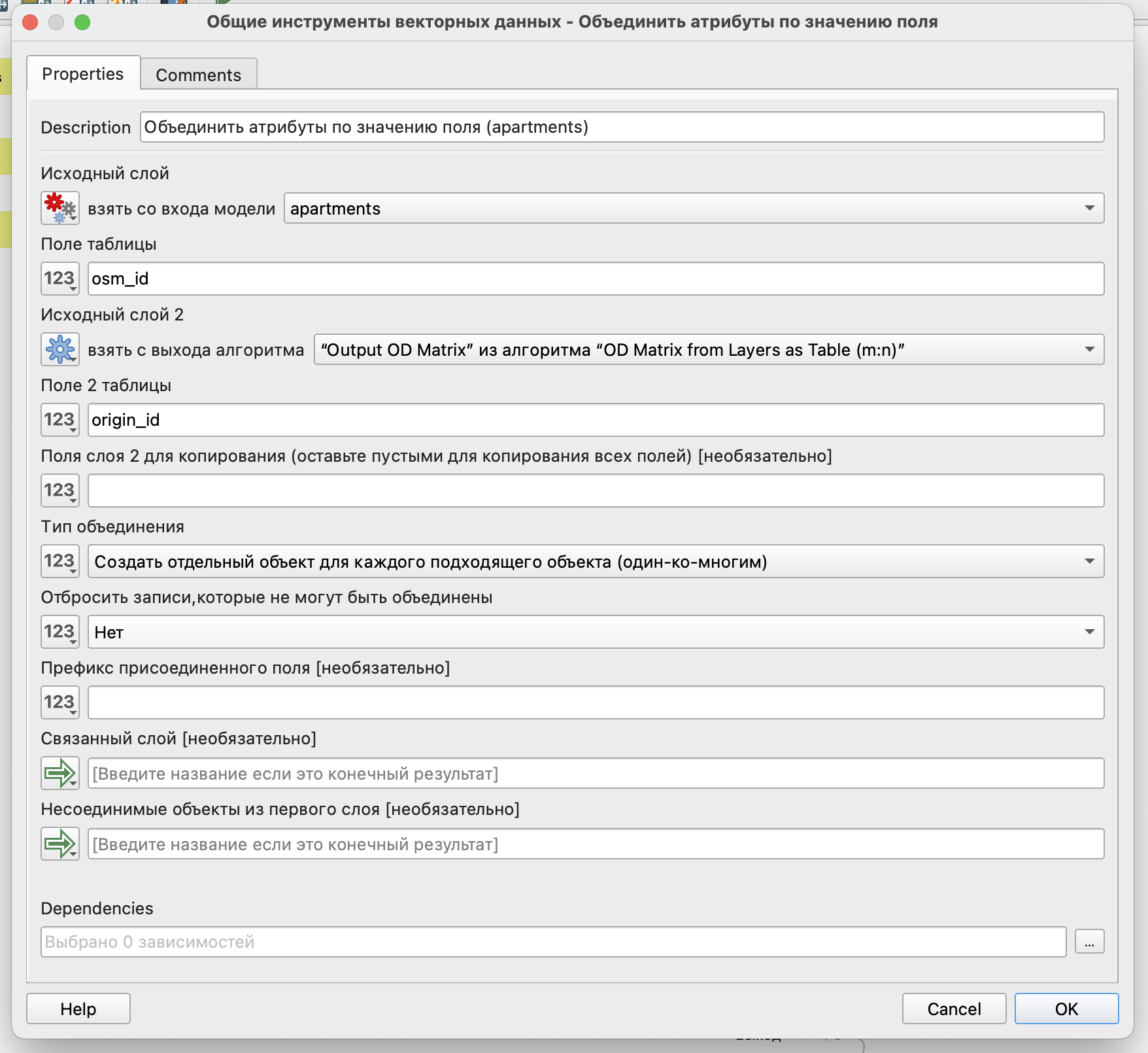
Так как мы будет рассчитывать вероятность посещения того или иного магазина для каждого из жилых домов, то основной расчет вероятности будет осуществляться внутри атрибутов жилых домов. Поэтому значения времени или расстояния из матрицы старт-назначение присоединим к слою жилых домов.
Присоединение будет осуществляться по совпадающим значениям полей: у исходного слоя есть osm_id, а в матрице есть origin_id - идентификатор стартовой точки, который был взят из osm_id исходного слоя.
2.3 Расчет вероятности посещения конкретного сервиса
Если мы обратимся к формуле в начале раздела, то увидим, что в формуле используется не только расстояние между потребителями и сервисом, но и площадь сервиса.
Поэтому атрибуты магазинов тоже следует присоединить к слою жилых домов.
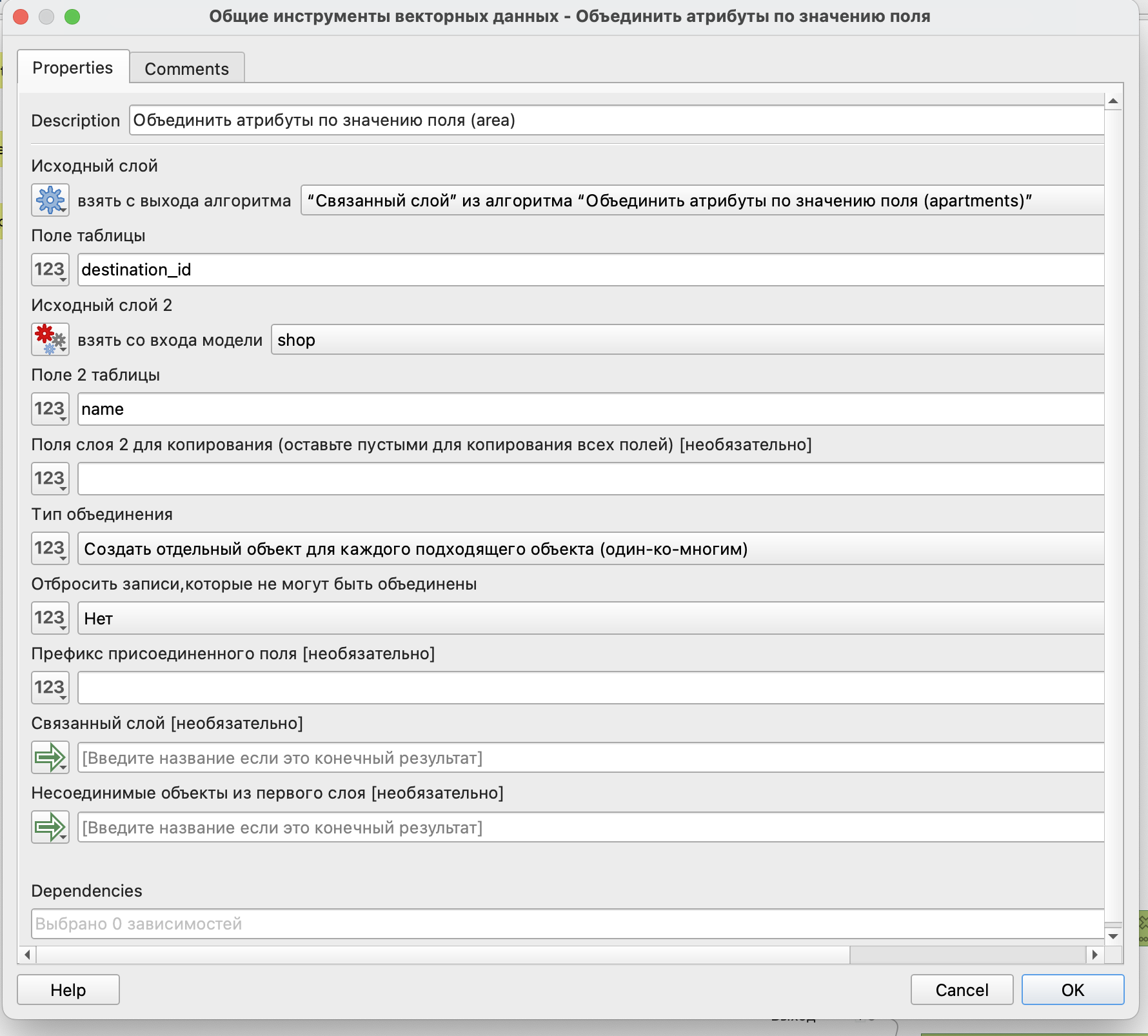
Присоединение здесь будет осуществляться по названию магазина к результатам предыдущего шага, поэтому в качестве связыющих полей будет использовано destination_id и поле name слоя с магазинами.
Обратите внимание, что тип объединения здесь один-ко-многим, то есть если с объектом исходного слоя совпадет более одного объекта присоединяемого слоя, то исходный объект будет продублирован и к нему присоединен атрибут второго совпавшего объекта.
В нашем случае это необходимо так как нужно рассчитать вероятность для всех магазинов и, если мы присоединим только первый совпавший по атрибуту, то в расчет мы сможем включить только его и таким образом получим безальтернативную вероятность посещения только одного магазина.
Для того, чтобы не запутаться в однотипных операциях в одинаковыми названиями, вы можете менять его в графе Описание (Description).
Следующим шагом рассчитаем числитель в формуле: \(\frac{S_{j}}{T^\lambda_{ij}}\), разделив площадь каждого магазина на время в пути до него с помощью калькулятора полей.
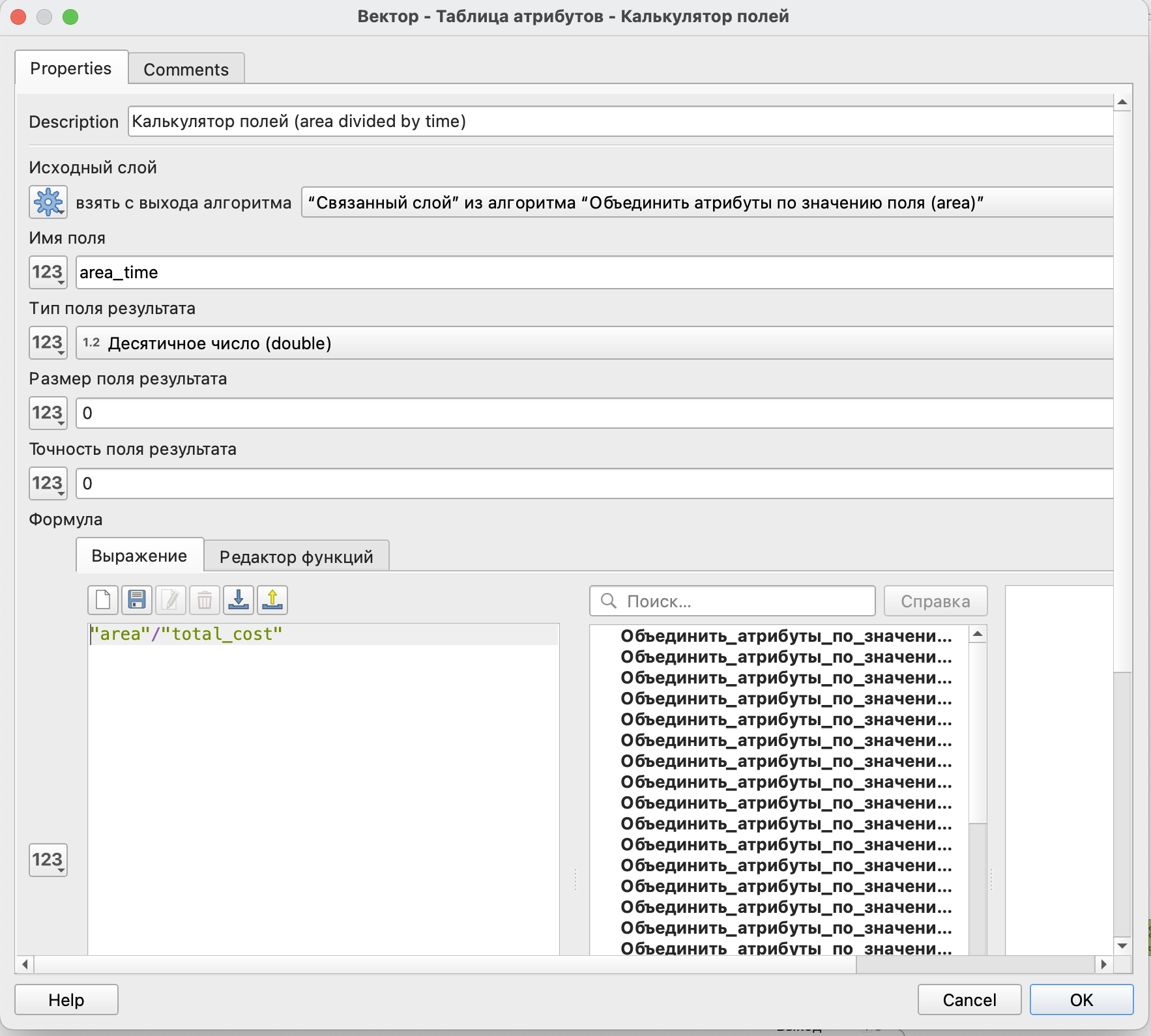
Калькулятор полей здесь устроен почти также как и стандартный калькулятор в таблице атрибутов. Все функции и формулы стандратны.
Обязательно здесь необходимо указать название нового поля и тип данных.
Следующим шагом нужно рассчитать знаменатель модели: \(\sum_{j}^{n}\frac{S_{j}}{T^\lambda_{ij}}\).
Для этого необходимо фактически просуммировать все полученные нами на предыдущем шаге значения, но только для каждого жилого дома и соответствующих магазинов. То есть нам нужно просуммировать не все значения по столбцу, а только значения соответствующие одному жилому дому.
Расчет осуществим с использованием SQL-запроса и оконной функции внутри него.
Оконная функция в SQL - функция, которая работает с выделенным набором строк (окном, партицией) и выполняет вычисление для этого набора строк в отдельном столбце.
Основное отличие оконной функции от группировки по параметру состоит в том, что количество строк в запросе не уменьшается по сравнении с исходной таблицей.
Подробнее можно почитать по ссылке.
Получается, что в нашем запросе сначала таблица будет поделена на группы строк, соответствующие одному и тому же жилому дому (имеющие один и тот же индентификатор дома), а потом суммирование значений будет производиться только в пределах этих групп строк.
Структура запроса:
select origin_id, destination_id, total_cost, area, area_time, geometry, sum(area_time) over (partition by origin_id) as summa from input1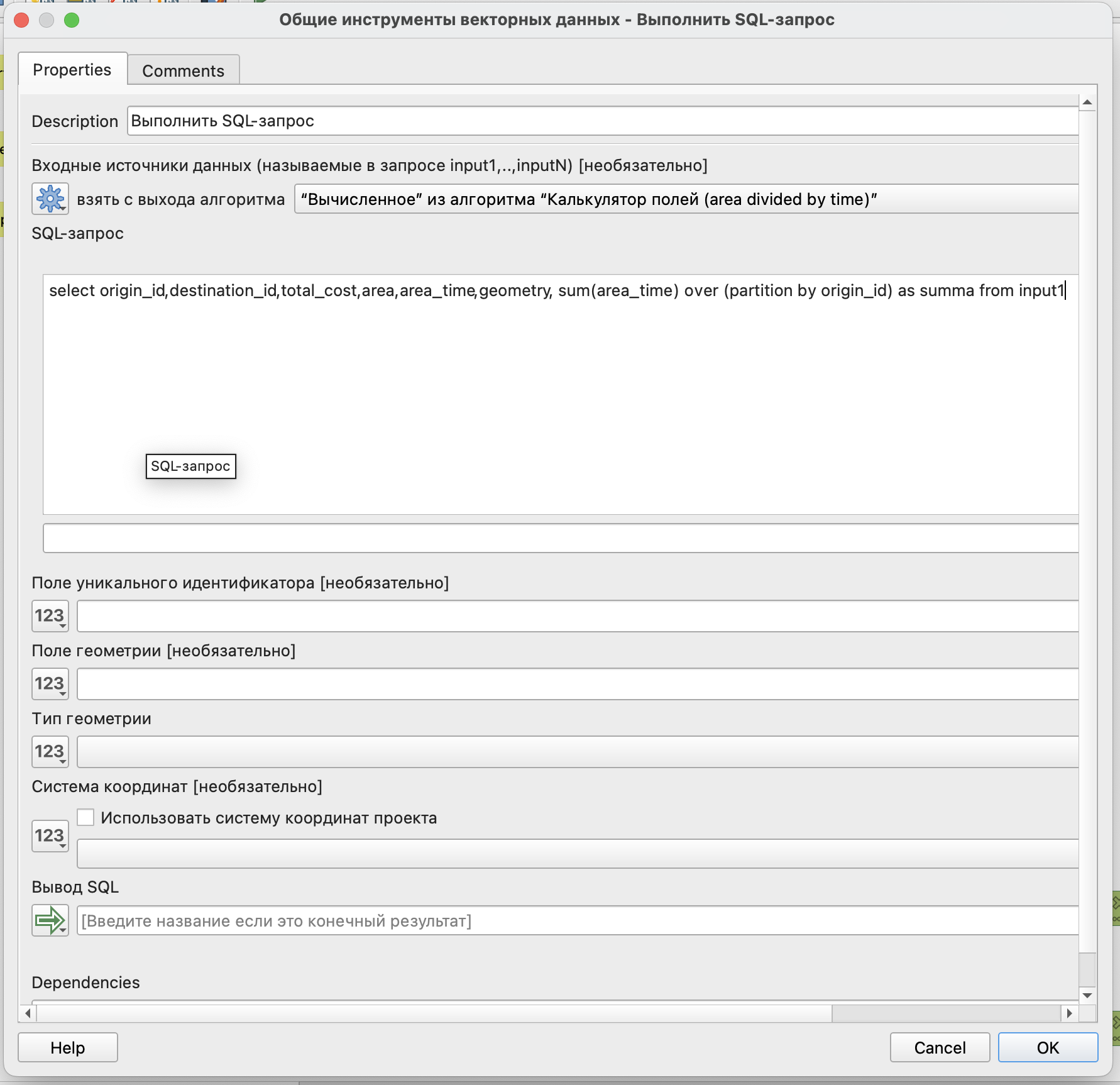
И последним шагом рассчитаем вероятность посещения того или иного магазина, еще раз использовав калькулятор полей и поделив друг на друга два полученных нами на последних шагах значения.
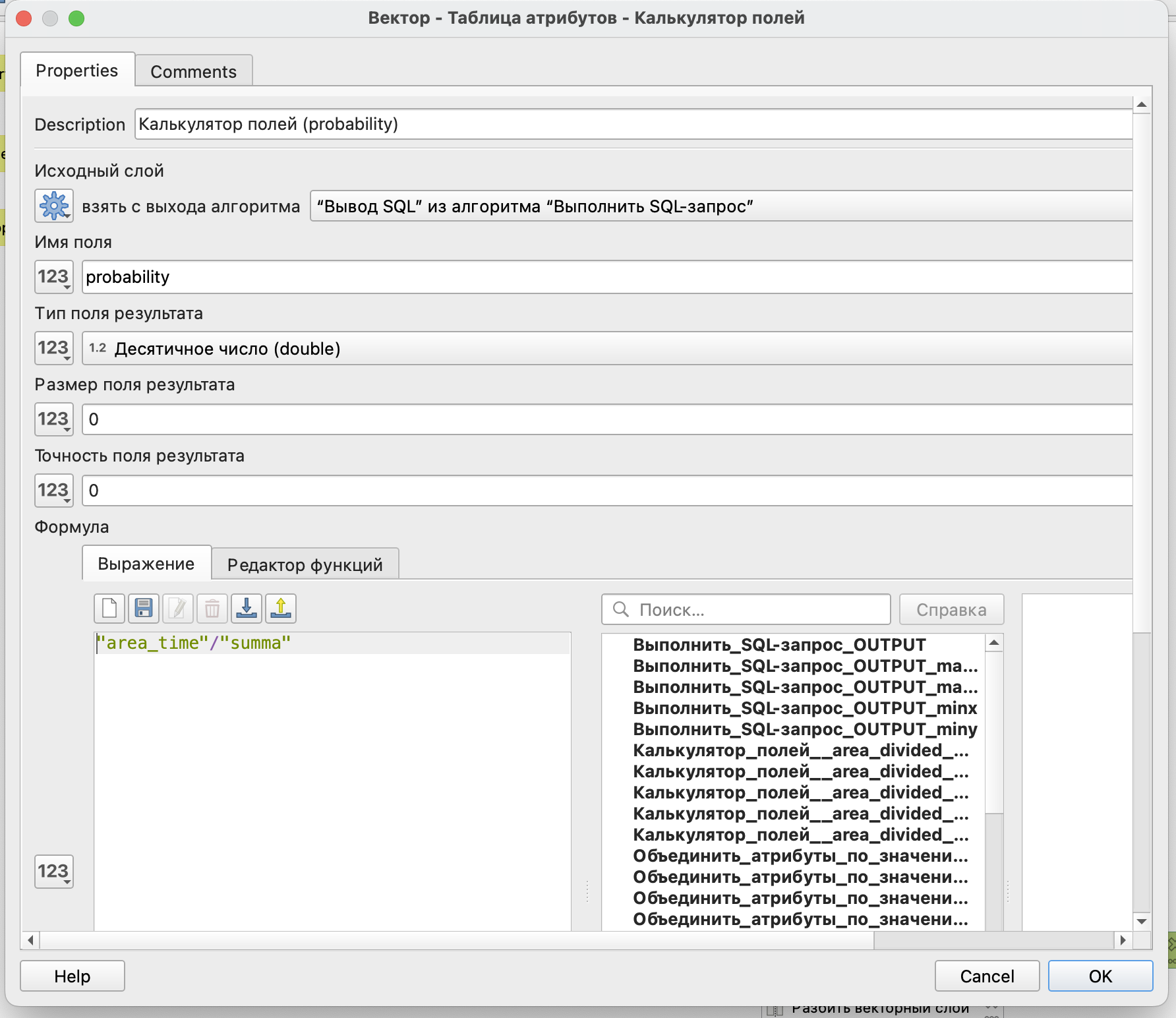
Этот результат уже можно рассматривать как итоговый и ввести его название, чтобы это считалось выводом всей модели.
Полученная схема модели показана на рисунке ниже.
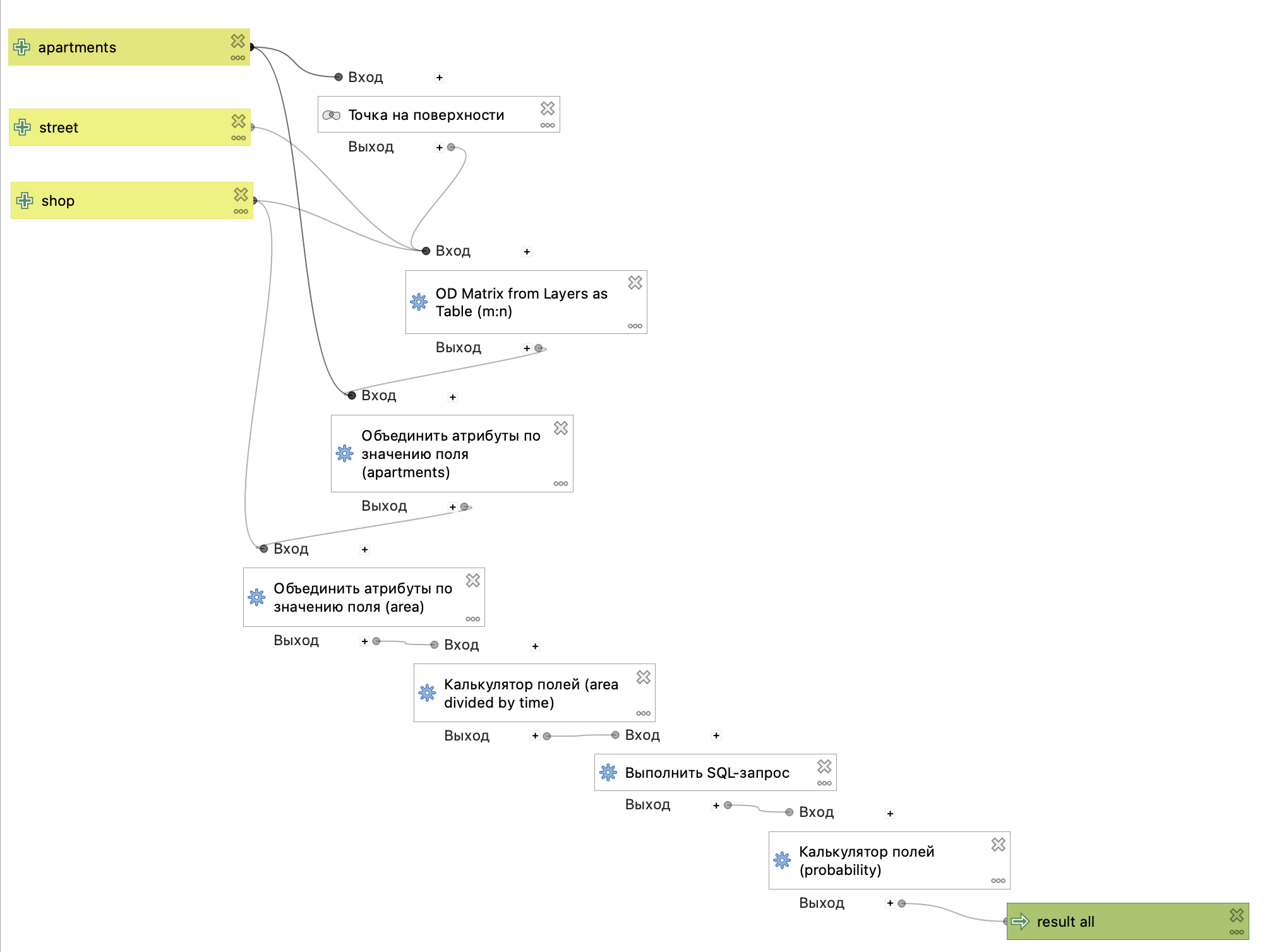
Перед запуском модель можно проверить командой из строки меню Модель \(\longrightarrow\) Проверить модель.
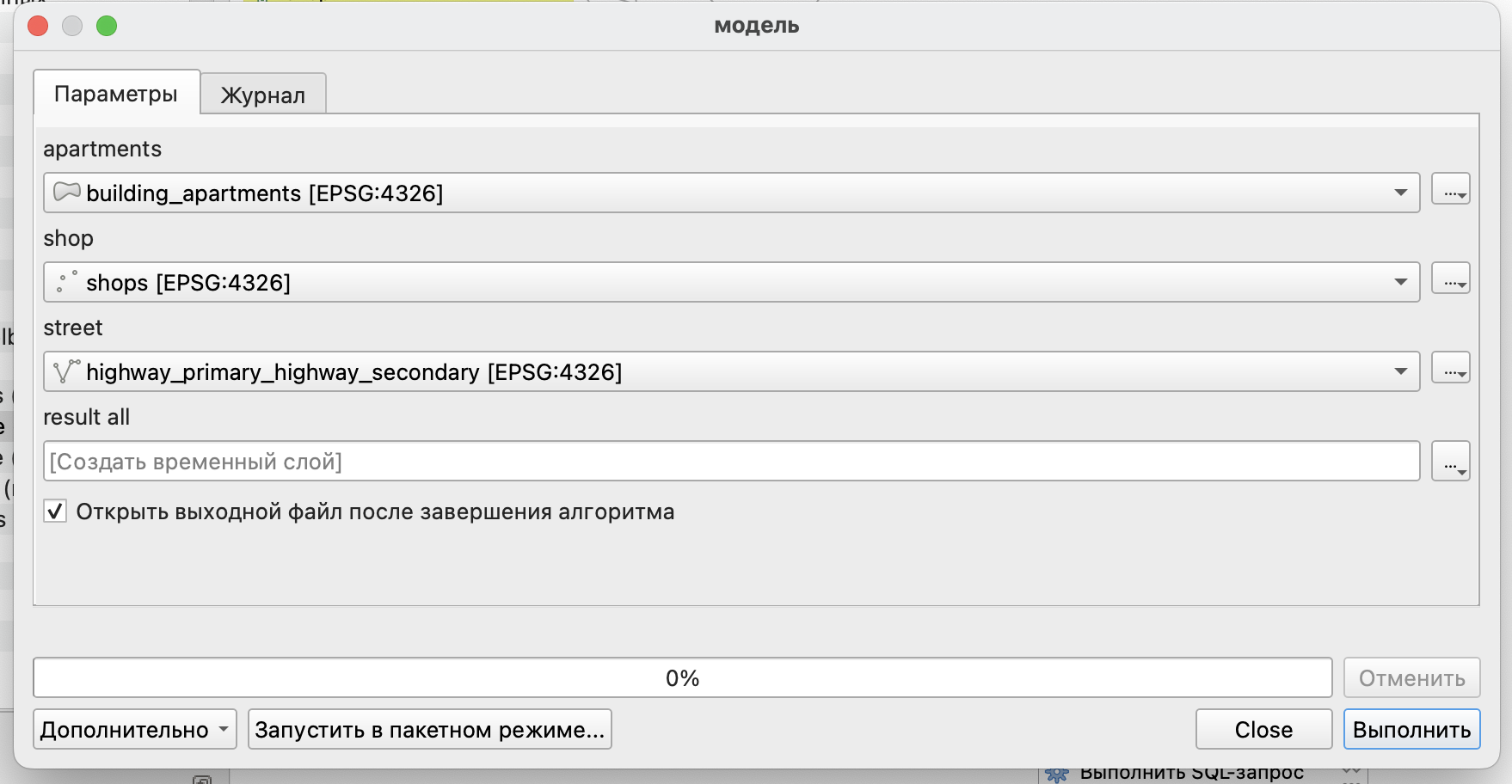
Запуск модели осуществляется либо по кнопке ![]() , либо из строки меню Модель \(\longrightarrow\) Запустить модель.
, либо из строки меню Модель \(\longrightarrow\) Запустить модель.
После запуска модель выглядит практически как стандартный инструмент из Панели инструментов анализа.
Полученный результат на карте будет выглядеть идентично исходному слою жилых зданий, так как использовалась их неизмененная геометрия.
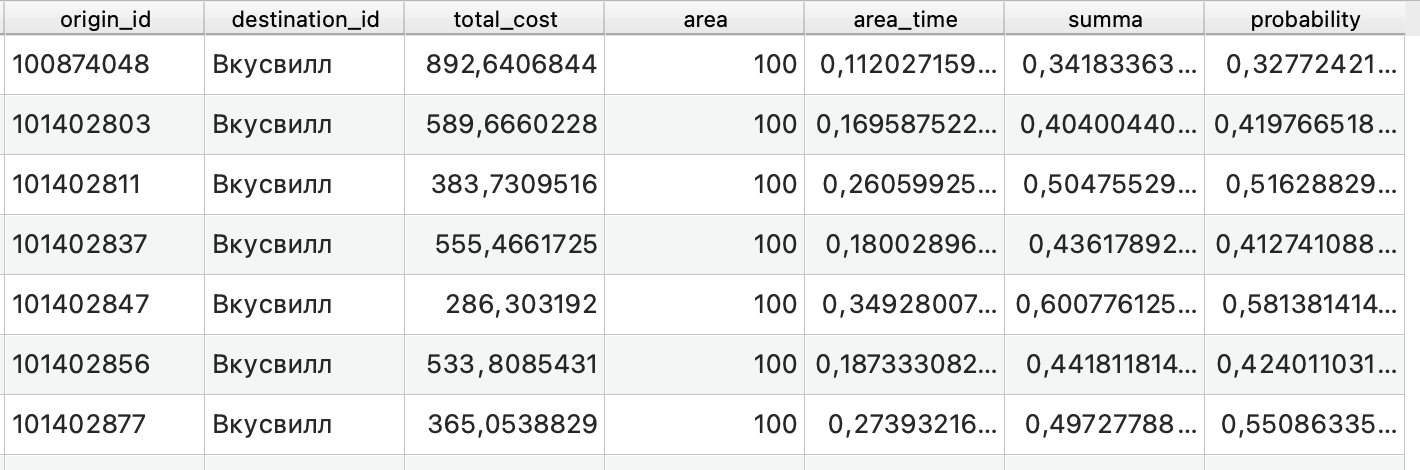
Самая интересная часть результатов - это атрибутивная таблица со всеми значениями.
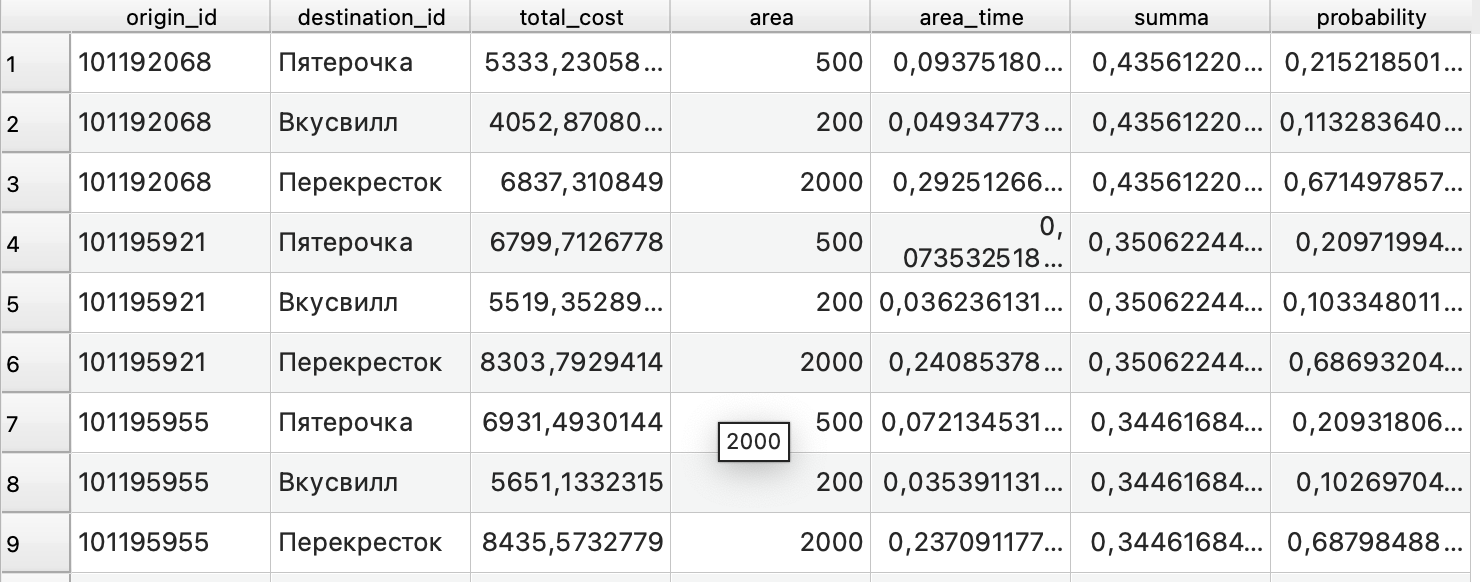
В этой таблице как раз можно увидеть повторяемость каждого из зданий (обратите внимание, что в колонке origin_id значения повторяются столько раз, сколько у вас было магазинов в примере):
origin_id - идентификатор дома из исходных данных;
destination_id - идентификатор (название) магазина из исходных данных;
total_cost - расстояние от конкретного дома до магазина из матрицы старт-назначение;
area - площадь магазина из исходных данных;
area_time - отношение площади магазина к расстоянию, рассчитанное на промежуточном этапе;
summa - сумма всех предыдущих значение для каждого дома;
probability - вероятность посещения конкретного магазина жителями этого дома.
Проверить корректность своих расчетов можно проверив два условия:
вероятность (последняя колонка может находиться только в пределах от нуля до единицы);
сумма вероятностей для каждого дома должна равняться единице.
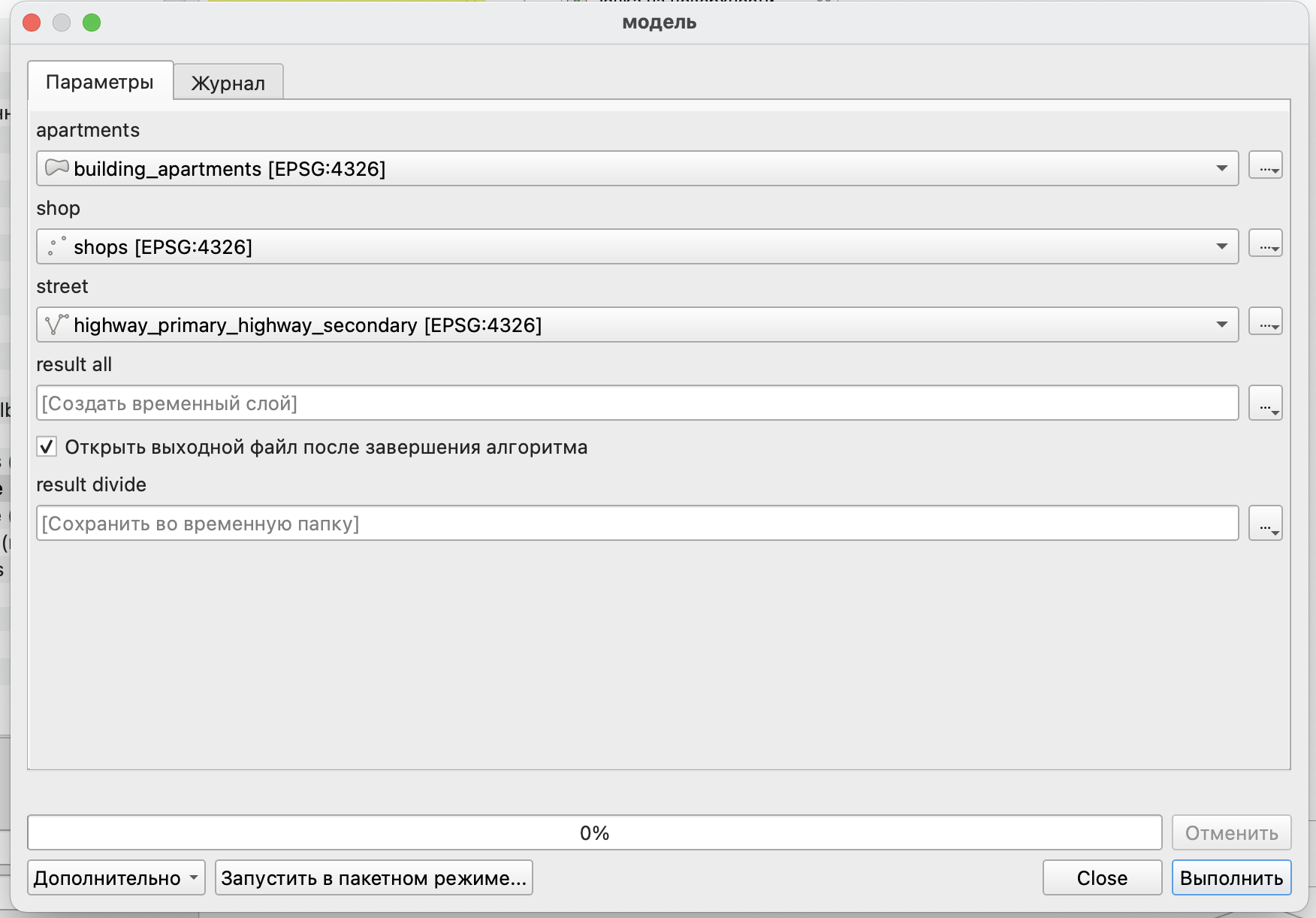
В качестве финального этапа можем разделить полученный в итоге слой так, чтобы для каждого из магазинов был свой отдельный слой.
Для этого воспользуемся инструментом Разбить векторный слой и разобьем его на отдельные слои по идентификаторам магазинов.
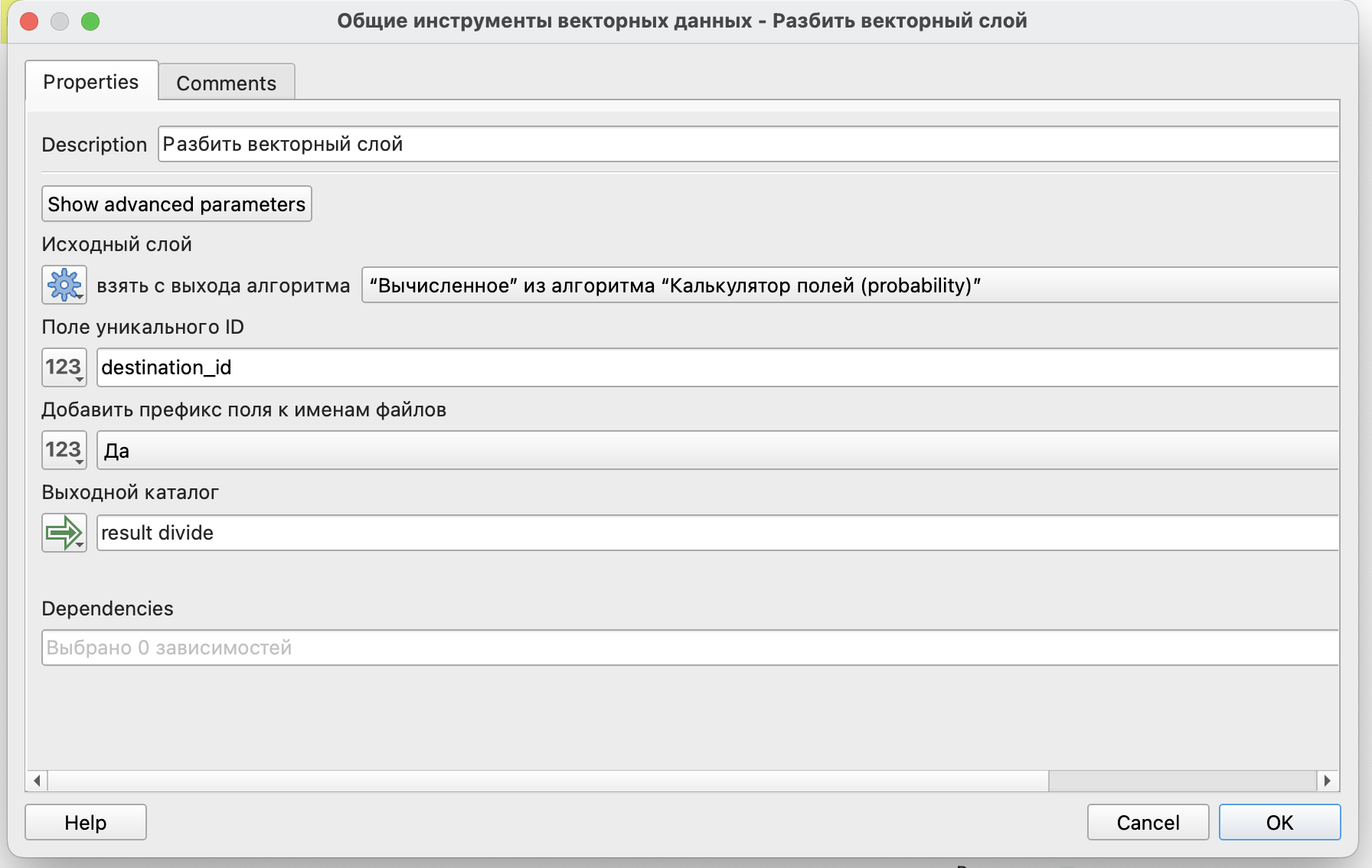
Здесь результат тоже будет выводиться как конечный.
Таким образом, по результату запуска модели будет выводиться слой, содержащий вероятности по всем домам и магазинам, и слои, содержащие вероятности по отдельным магазинам (этих слоев будет столько, сколько было магазинов в исходном слое).
При необходимости вы можете сделать столько выводов из модели, сколько посчитаете нужным.
Окно запуска модели немного изменится: в нем появится возможность выбора папки для сохранения наших результатов разделения слоя.
В выбранной папке по результатам работы модели появятся файлы с префиксом destination_id_ и названием магазина: 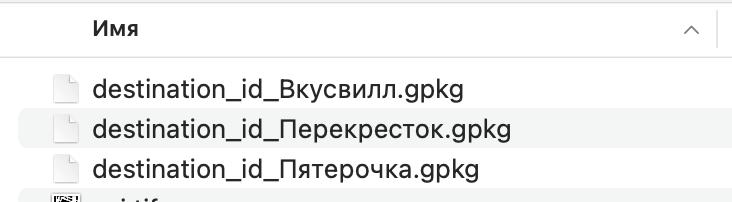 .
.
Атрибутивная таблица сохранит свою структуру, но, естественно будет содержать только данные по одному из магазинов.
Полученная модель может быть сохранена как отдельный файл в формате .model3 (Модель \(\longrightarrow\) Сохранить модель как) или как часть проекта (Модель \(\longrightarrow\) Сохранить модель в проекте).
Если бы было известно количество жителей в каждом доме, то можно было бы рассчитать потенциальное число покупателей для каждого из магазинов по формуле:
\[ E_{ij} = P_{ij}C_{i} \]
где \(E_{ij}\) - предполагаемое количество покупателей из локации \(i\), которые пойдут в магазин \(j\);
\(P_{ij}\) - вероятность того, что покупатель из локации \(i\) пойдет в магазин \(j\);
\(C_{i}\) - количество покупателей в локации \(i\).
Рабочий пример геомодели можно скачать по ссылке.
Обратите внимание на названия полей для таблицы в магазинами в геомодели - они такие же, как описаны выше в тексте, если вы называли их по-другому, то их нужно исправить в геомодели.